The Tree List Component:
Loading Data
By David Swain
Polymath Business Systems
In the last issue of Omnis Tech
News, we examined some basic properties of the Tree List component,
but we only populated that component using the treedefaultlines
property in the Property Manager. This is not the way to
go for most real-world uses of this component. In a database application,
we would most likely want to populate a Tree List component with
values retrieved from the database - and do so in some meaningful
way. So this month we will explore some strategies and techniques
for getting database content into a Tree List field.
But first it might be helpful to see how we can get our static
content from last time into a List variable as a transfer conduit...
Transfer Static Tree to List Variable
While a List variable is not the direct data source for a Tree
List component, we have been provided with methods for transferring
hierarchical data to and from a Tree List in a format that a List
variable can handle. As a first step to learning how to populate
a Tree List component with data, let's extract the contents of the
static tree we set up in the last article into a List variable and
examine those contents.
The Tree List component contains a method named $getnodelist()
that performs this operation for us. This method requires three
parameters and, on execution, appropriately defines and populates
a List variable to contain an image of part or all of the contents
of a Tree List field. In the order they must be given in the parameter
list of the method, here is a brief description of each parameter:
Parameter definitions for $getnodelist()
| listmode |
The first parameter determines the format of the
List variable as well as the content returned by the method.
It accepts either a special Omnis "Tree field" constant
or the numeric equivalent of one. The two constants that we
will use in this article are kRelationalList (0) and
kFlatList (1). These will be explained in detail below. |
| noderef |
This is usually a notational reference to a specific node
within the tree. But in the special case where we want to address
the entire tree (which we do here), we supply an explicit value
of 0. This parameter implies that we can extract any
branch of our tree into a List variable. This becomes important
as we develop techniques for populating a Tree List field when
the user clicks a "closed" disclosure icon to open
(or expand) a node. |
| listname |
The name of the List variable that we wish to hold our tree
image. This variable must be in scope when the method is executed,
but can be of any level of scope. In this article we will generally
use an instance variable for our examples. |
The two listmode constants mentioned above need a bit of clarification.
So we can try both of them to see what they yield. If we execute
the following code then after defining two appropriately named List
variables of instance scope), we can examine the contents
of our static Tree List from the perspective of a List variable
in each of these modes:

This method builds two lists based on the full contents of our
static Tree List field: one using the kRelationalList constant
and one using the kFlatList constant. We can use these
views to learn the differences between these two techniques/formats.
This knowledge will serve us well in making some decisions in "reversing"
the process a bit later...
Relationallist vs Flatlist
As a reference, let us first review the expanded content of our
Tree List field. Here we see it with all nodes expanded:

Fully expanded static tree list
If we count them all, there are 14 nodes in this tree. We can see
the names of all the nodes in the illustration above. Now let's
look at the "relational" list view of these contents:
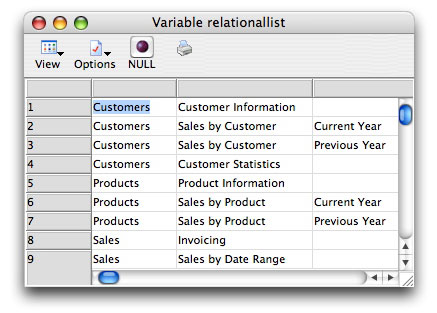
Relational list of static tree contents
The relationallist value derived using $getnodelist()
displays only the leaf nodes (those at the end of a branch
that do not have children of their own), giving the complete hierarchical
path to each in columns to the left of the name of the leaf node.
There are only 9 leaf nodes in this tree, so that is the number
of lines in the extracted List value. Parent nodes are not given
a separate line in this list. Each column represents a level
with the tree hierarchy. Notice that leaf nodes can be at any level
in the tree. (Even a root node can be a leaf node, although this
would be rare.) The name of each node at each level along that branch
is listed, but we only see the names of the nodes,
not any of their other property values, in this list extraction.
This view summarizes the relationships among the nodes, but provides
few details. Still, as we shall shortly see, this can be an effective
format for quickly populating trees with nodes.
Now let's examine the "flat" list view of the Tree List
contents:
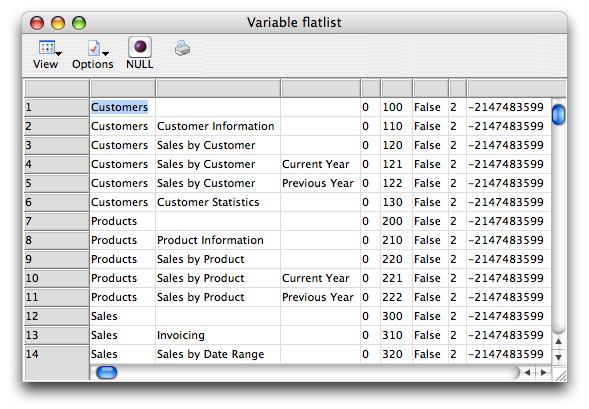
Flat list of static tree contents
The flatlist extraction shown here displays a line for
each node, whether it contains other nodes or not. Any
node that is not a root node (a node with no parent node)
includes columns that detail the path back to the appropriate root
node. (This is for the special case of loading the contents for
the entire tree. We will see how this varies if we point the $getnodelist()
method to a specific node shortly.) But the flat list view gives
us some useful information beyond a more verbose listing of node
paths.
This view also shows us a number of property values for each node
in five additional columns beyond the one required by the deepest
leaf node level. While these columns have not been given names in
our List variable, the Omnis Programming manual gives us some brief
details. In the order in which these columns are added, here is
a little more discussion of each of those properties:
Property columns for lists derived using kFlatlist
| $iconid |
If a node icon were being used in
our Tree List, the full value of the icon id (an integer value
that often includes a size constant offset) would be given in
this column. Since we are not using this feature in
this example, the value is 0. |
| $ident |
We assigned these values when we
manually built the Tree List content for the last article. It
was important to assign unique values so that we could detect
precisely which node was selected when using the $currentnode()
method. This property is empty if it is not specifically assigned
by us - unlike most other $ident properties in Omnis
Studio. |
| $enterable |
We did not make the nodes of our
Tree List enterable, so this property is set to kFalse
for each node. But the implication here is that it could
be set to kTrue - and on a node-specific basis. If
it were, the end user would be able to change the text of the
label (and, therefore, the $name property value) for
a node. |
| $expandcollapse |
When extracting node information
from an existing Tree List, this column shows the current state
of each node. (There is no real property with this name, but
the name describes the state of the node represented by this
column.) The value of 2 shown here is the numeric equivalent
of the constant kTREEnodeExpanded. Each parent node
was already expanded when we used $getnodelist() -
and each leaf node is considered to be expanded as well. An
unexpanded node that has at least one child would return a value
of 0 for this property. |
| $textcolor |
This property gives the base text
color for the label of each node. The negative integer value
shown here is the numeric equivalent of the Omnis Studio system
color constant kColorDefault. |
Sop we see that the kFlatList technique of extracting
Tree List contents into a List variable gives us a lot more detail
than the kRelationalList technique. This may come in handy
later - but only if we explore the use of $getnodelist()
a bit further...
Examining an Individual Parent Node
So far we have used the $getnodelist() method to retrieve
all the nodes from a Tree List field. But we can use that
second parameter to point to a specific node. Let's see
what that does for us.
We will skip the obvious intermediate steps (or we might never
get past this point!) and go directly to a node that contains only
leaf nodes. A good candidate is the node labeled "Sales by
Customer". It contains only "Current Year" and "Previous
Year" nodes (with $ident values of 121 and
122 respectively). After adding an Item reference
variable that points to the tree list (to cut down on the length
of our code lines), we can create a new pushbutton that retrieve
our two lists for the currently selected node:

If we select the "Sales by Customer" node on our window
instance and then execute this code, we will see the following two
lists:
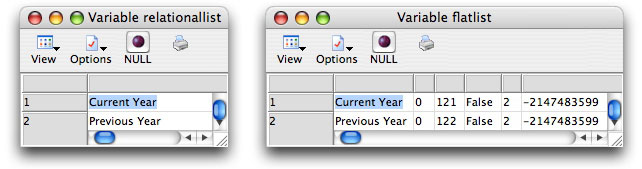
Relational and flat list extractions from a node containing
only leaf nodes
Now we see only the child node information in our extracted list.
The path to each child from its original root node is not needed
because it is assumed that we already know this information (since
we pointed to the parent node to retrieve the list in the first
place). Note that the name of the node is now the only
thing we see in the "relational" list, while we still
see all the properties associated with the nodes in the
"flat" list.
So What Was the Point of All This So Far?
Seeing what we can retrieve using $getnodelist() is a
quick way to understanding how we can build Tree List content from
our databases. You see, the $getnodelist() method has an
updating counterpart: $setnodelist(). If we understand
the output of the one, we are many steps closer to being able to
use the features of the other!
The $setnodelist() method uses exactly the same parameter
set as does $getnodelist(). We can use lists formatted
exactly as we have seen to either populate an entire tree, populate
a single node with children or something in between! All we have
to do is to load a List variable with the appropriate information
and then point $setnodelist() at the appropriate node to
add that content to a Tree List field. And we can do this either
for the entire tree (using a value of 0 for the node parameter)
or to simply populate a given node with child nodes, just as we
have so far extracted either the entire tree or just the content
of a specific node.
But first we need to consider how we might retrieve that information
from our database into a List variable. Remember, a tree is hierarchical
in nature and we don't have any commands designed to deal with multiple
hierarchical levels of data directly. There are at least two basic
strategies we might use for dealing with our data hierarchically:
build the entire tree content into a List variable and then transfer
it to a Tree List or build each nodes contents as we need it. Each
of these approaches also depends on the nature of our data in the
first place - and there are at least two hierarchical structure
types that we might encounter in our work. We need to understand
these structures before we venture further...
Hierarchical Data Structures
There are many examples of hierarchical data structures in the
world. Just because we are using a relational database doesn't mean
there isn't a hierarchical aspect to our data - there usually is!
We will juxtapose the two most common hierarchical approaches here:
Parent-Child Relationships
By far, the most common hierarchical aspect of a relational database
is the parent-child relationship itself. While there are other relationships
we might discover (or concoct) among the tables in a database, the
primary-foreign key relationship is strictly hierarchical. Each
parent has the potential for having multiple children, while each
child has exactly one parent row in a specific parent table. Even
in the special cases where we restrict a parent to only one child
or allow a child without a parent, we can still consider this to
be hierarchical. Here are some simple examples:
In a personnel database we might have tables for Divisions, Departments,
Groups and Employees. Here the hierarchy is clear and unambiguous
(as long as an employee belongs to only one group, etc.). Except
for Employees, each node is assumed to be expandable. The only leaf
nodes would be the Employees nodes.
In a tOmnis Softwarebase we might have tables for Courses, Classes
and Students. Since there is a Many-to-Many logical relationship
between Classes and Students, we would also introduce a Registrations
table to mediate that relationship. Our hierarchy here would then
be Courses, Classes and Registrations, but we could also retrieve
the appropriate row from Students for each Registrations row added
to our tree. Again, the only leaf nodes would be at the Registrations
level (assuming that all Courses have at least one Class and that
all Classes have at least one Student, of course).
But there is another hierarchical structure that we might come
across...
Single-Table Reflexive Relationships
Occasionally we might encounter a table that itself requires hierarchical
handling. This is the case when records from that table are related
to records from the same table - and there is no additional table
required to manage these relationships. Such a relationship is said
to be a reflexive relationship. (I thought I had made up
this term years ago, basing it on a linguistic principle. I was
pleased to see, while researching this article, that it is truly
a formal set theory term - and it is even used the way I have always
described it!) Here are a couple of examples as illustrations of
this type of data:
In a database that tracks Equipment, we might want to handle "subassemblies"
as separate items within the same table (because we would track
the same maintenance processes for a subassembly as for its parent
assembly). We would include additional columns in this table for
superassembly and isSuperassembly to handle these
internal relationships. The superassembly column would
point to the primary key value of the parent for a given row. If
a row has no parent, a value of 0 would indicate that it
is a "root row". We could use such root rows to populate
a dynamically built tree with its initial nodes, for example. The
isSuperassembly column value could be used to determine
whether to give an associated tree node a disclosure icon (that
is, whether the node created to represent the row would be a leaf
node). In traversing the hierarchy during some iterative process,
the value of this column in a particulr row also lets us know when
to turn back and go down another branch of the hierarchy.
There are a number of businesses and organizations where it is
important to track referrals or sponsorship lineages in a Members
or Customers table. Often there are commissions or other benefits
that accrue to those people who have enlisted others and we must
have a way of determining their qualifications for such benefits.
To do this, we must add columns for sponsorID and isSponsor.
The sponsorID is given a special value for "primary"
members (those who have no sponsor - or who were directly sponsored
by the person who owns the business for which the Omnis program
is used) and the isSponsor defaults to kFalse
for each new member. When one member sponsors another, that member's
isSponsor value is then set to kTrue and the row
for the new person they sponsored contains their ID value
in the sponsorID column. This allows us to follow a lineage
up and down the chain.
An important thing to note about these single-table hierarchies
is that the number of levels that may be involved is only limited
by the data we collect. This means that these hierarchies can be
quite deep within this single table. In building and manipulating
trees based on such data, we do not have to worry about which table
to access for which node level. All nodes are derived from the same
table. But there is no assurance of the number of levels we may
need for building our tree. So if we wish to use the kRelationalList
technique for building an entire tree at once, we would need to
dynamically expand the number of columns in our transfer list as
we encounter deeper levels of the hierarchy. We may well decide
that this is not the best path to follow...
So we now have some idea of how our data can be viewed hierarchically.
Now let's examine how we might get that data into a Tree List field.
Build List for Mass Transfer to Tree List
Constructing a list to fully populate a tree list in one pass is
manageable when using a multiple table hierarchy because the number
of columns required for the transfer list is fixed and known ahead
of time. But this still can be unwieldy in practice for a hierarchy
of any complexity. Building a tree from such structures, we access
a different table for each level of the tree. We can use the primary
key value for a row within the table for a given level as the $ident
value for the node that represents that row (assuming that we use
Long integer primary keys, since that is the data type
of the $ident node property...). If we know the $level
of a node, we know from which table its $name and $ident
values were derived and we can easily find that row again (or that
rows parent or children in the appropriate table) based on these
values.
Building the entire tree for a multiple table hierarchy is easy
using the kRelationalList technique, especially when working
with a SQL data source where we can build the relational list content
with a simple JOIN on the tables involved - and including an ORDER
BY clause that properly clusters the result set at each hierarchical
level. Of course, we cannot provide any property values for a node
other than the $name property value using this technique.
But if the name of a node is unique at its level of the hierarchy,
this will work just fine to identify the row for the node (since
we know which table to use for that level).
Populating the full tree for a multiple table hierarchy using the
kFlatList technique is a bit more complicated. We need
to "walk the tree" and add a line to our transfer list
for each node. While this allows us to specify property values for
each node at every level of the hierarchy, it is a lengthy process
using any data source. This laborious process can be performed
more easily with native Omnis techniques. It is not practical for
SQL.
Building an entire tree in one pass for a single table with hierarchical
content can be an even more difficult proposition. The main reason
that it is difficult to handle the entire hierarchy is because the
number of levels - and, therefore, the number of list columns required
for our transfer list - may not be known at the outset. It can also
only beperformed using the "walk the tree" technique -
and so is generally not considered viable for large hierarchies.
But there is a better way...
One Node at a Time
For large, complex hierarchies, building the entire tree for all
the data in a hierarchy is usually not practical. In addition to
the complexity of building the content for the transfer list, the
final Tree List may require a tremendous amount of RAM and the user
may only need to access a small portion of the tree along only one
branch. It is usually much more efficient to build the tree one
node at a time, starting with a set of root nodes and adding content
to an individual node as the user attempts to expand that node.
Using the kFlatList technique allows us to assign property
values to each child node as part of the process - including a property
value that forces the display of a disclosure icon for those nodes
where we expect child rows may exist.
Following this strategy, we initially present our Tree List with
only root nodes. So we need a constructor method to retrieve and
properly format that content. The collection of such nodes will
have a common characteristic () that we can use to retrieve images
of the corresponding rows from our database using a simple SELECT
or Build list from file process followed by $setnodelist()
with a second parameter value of 0. The kFlatList technique
works best for this because we can specify a $ident value for each
node as a link back to the row in the database that the node represents.
We can also set the expandcollapse column value in our
transfer list to kExpandCollapseAlways (1), which forces
a disclosure icon to appear even though there are currently no child
nodes that could be exposed. This assumes that there could
be child rows in the database for that node.
We then react to the user expanding and collapsing a node by building
or removing the content for just that node. Adding the content for
an individual node is again a simple matter. We have already placed
the primary key (or some other unique identity) value in the $ident
property for existing nodes, so we can know that value for the node
the user wishes to expand. Armedwith that value, it is a simple
matter to retrieve the appropriate information for all child rows
that point to the row associated with that node.
If we can know ahead of time whether a newly introduced node will
have children, we can give that node a disclosure icon. If we do
not do this, the user will not be able to expand that node. Of course,
the node would automatically display such an icon if there were
child nodes present, but with this technique, we only want to indicate
that there should be child nodes. If we cannot know this,
it is safest to include the expand-collapse icon with all
nodes.
Expand and Collapse Node Events
But how do we know that the user wants to expand or collapse a
specific node? There are two additional Tree List events that we
must use to make our node-specific tree building process work. These
are the evTreeExpand and evTreeCollapse events.
Theswe are events of the Tree List field itself, but each of these
events is accompanied by a pNodeItem event parameter that
points to the node in the tree for which the event was activated.
The pNodeItem parameter is of Item reference data
type, so we can use it to both retrieve the $ident value
for the target node and then supply it as the second parameter of
the $setnodelist() method for adding child nodes.
So using the kFlatList technique, the process for adding
a new level of hierarchical content when the user expands an existing
node would voil down to:
On evTreeExpand
; Perform tests to determine where we are
in the tree and what row is represented here
; Perform operation that populates our transfer
list with the next hierarchical level content
Do treeref.$setnodelist(kFlatList,pNodeItem,transferList)
The method for building the next hierarchical level of content
into a "flat" list is usually relatively simple, since
we only need to retrieve the children for the current node and determine
which of these might have children (so that we can provide a disclosure
icon that the user can "expand"). Both native Omnis and
SQL techniques for retrieving child row content are straightforward.
For multiple table hierarchies, the level of the expanded node determines
both the table from which the children will be fetched and whether
a disclosure icon is required for each child node. For single table
hierarchies, the value of the "end-of-branch" indicator
column is used to determine whether a specific child node gets a
disclosure icon.
Good Housekeeping
Of course, if we are going to add child nodes to a specific node
every time it is expanded, then we must also remove all
of its child nodes when it is collapsed. Otherwise we would build
up multiple sets of child nodes within each node over time! Fortunately,
Omnis Studio offers us the $clearallnodes() method for
just this purpose.
The $clearallnodes() method is very simple. It is a method
of a Tree List node rather than of the Tree List field
itself, so it requires no parameters to point to the node it is
to clear. (Apply directly to the tree node...) In fact, it takes
no parameters at all! And it clears all levels of nodes from within
the node to which it is applied. We simply apply it to pNodeItem
within an evTreeCollapse event as shown here:
On evTreeCollapse
Do pNodeItem.$clearallnodes()
This code is completely generic, so it can be pasted anywhere we
need this functionality. But we do have to be careful. If we mistakenly
apply this method to the Tree List field itself, it will clear all
the nodes (as advertised!) from the entire tree - including
any root nodes. We would have no nodes left to expand, so the Tree
List on our window instance would become completely useless to us.
Just a word of caution...
On the other hand, applying $clearallnodes() to the entire
Tree List is most appropriate if we are updating the entire tree
with new content using the kRelationalList technique at
the root level. There is a use for most everything in Omnis Studio!
(Pseudo) Code Samples
I couldn't let this subject go by without giving you at least some
generic sample code (or pseudo-code at least) to illustrate the
techniques I advocate here. I break these down into the two basic
types of hierarchical data structures already mentioned.
Here is an example of building a tree dynamically from a multiple
table hierarchy. Each tables rows are represented on a different
level of the Tree List field. In the conversational example given
earlier in this article, the root level would be the division
level, so we would initially populate the tree with just nodes retrieved
from the Divisions table. Each of these is assumed to contain at
least one department, so all nodes would be given disclosure icons
by default.
Initial setup (most likely in the $construct method):
; Initially define transfer list to contain
columns for kFlatList transfer
; for example, {nodeName,nodeIconID,nodeIdent,nodeEnterable,nodeExpandCollapse,nodeTextColor}
; retrieve root node content from database
Do $cinst.$objs.treelistfield.$setnodelist(kFlatList,0,transferList)
When a node is expanded, we need to know first which level of the
tree contains that node. This determines which table will be used
to retrieve child node information. This would normally be a simple
selection of rows (or list build) based on the equality of the target
nodes $ident value and the child tables foreign key column.
Because different tables and columns are involved at the different
levels, I generally use a Case block and call appropriate subroutines
as follows:
$event Method for Tree List:
On evTreeExpand
Switch pNodeItem.$level
Case 1 ;; division
Do
method getDepartments (pNodeItem)
Case 2 ;; department
Do
method getGroups (pNodeItem)
Case 3 ;; group
Do
method getEmployees (pNodeItem)
Case 4 ;; employee
;
this level can't be expanded
End Switch
Redraw {structureTree}
On evTreeCollapse
Do pNodeItem.$clearallnodes()
getDepartments Method (for example):
Calculate nodeExpandCollapse as kExpandCollapseAlways
;; or change for all lines after populating them
; Retrieve child data into the transfer list directly
; or into a separate list and copy the name and id values into the
transfer list from there
Do $cinst.$objs.treelistfield.$setnodelist(kFlatList,pNodeItem,transferList)
The exact retrieval code will vary depending on the back end database
and other factors. The subroutines for each level will be very similar.
When retrieving the lowest level, we would set nodeExpandCollapse
to 0 to suppress the disclosure icon.
For single table hierarchies, we would do things a bit differently,
but not radically so. We would still initially set up the highest
hierarchical level of nodes based upon appropriate criteria, then
trap the evTreeExpand event to populate agiven nodewith
children:
On evTreeExpand
Do method expandGroupNode (pNodeItem.$ident)
On evTreeCollapse
Do pNodeItem.$clearallnodes()
expandGroupNode Method:
; Retrieve child data (including name, id
and end-of-branch value) into a separate list
; for each retrieved line, copy the name and id values into the
transfer list
; set nodeExpandCollapse as kExpandCollapseAlways if end-of-branch
warrants it (otherwise 0)
Do $cinst.$objs.treelistfield.$setnodelist(kFlatList,pNodeItem,transferList)
The main difference is that we must determine which nodes are ultimately
leaf nodes so that we don't allow them to be expandable.
Then again, this is only a user interface refinement that may not
be a concern in some cases.
Next Time
I hope this helps you to use the Tree List component better. There
is more to tell, but it will have to wait for another time. In the
next article we will examine other events, features and uses of
the Tree List component, including the multi-column feature of this
useful tool.
| 
 Please logon or create a free account to download this file.
Please logon or create a free account to download this file.
 Facebook
Facebook Github
Github Instagram
Instagram Linkedin
Linkedin Twitter
Twitter Youtube
Youtube